

Competent intelligence is here, will it do engineering?
Let's stop arguing differences between natural and artificial intelligence and start exploring how to best use the technology
不管黑猫白猫,捉到老鼠就是好猫
It does not matter if the cat is white or black. It is a good cat if it catches mice. (Deng Xiaoping).This is English translation of a post I originally composed in Turkish.
-+-+-+-+
I was going to write on a different topic, but two recent developments changed my mind:
OpenAI introduced GPT-4.
Stanford University has made a new GPT program called ALPACA available to researchers. Discounting the time of the five PhD students who did this job in a few weeks, the cost to the university was $600 in cloud computing fees.
GPT-4 was expected, but ALPACA was a surprise. Stanford University now has made technology accessible to almost everyone, not only giant corporations. If it cost the university $600 to do it, there are those who ask why Microsoft pays 20 billion to OpenAI.
I will continue on what I started in my 12 December 2022 ve 30 December 2022 posts but with more technical detail.
First, I should address this artificial-natural intellligence dilemma. I do not think we need to discuss this yet. There is still time for programs to come that will learn everything on their own and then develop better software excelling themselves. Computers have just learned to speak, and it will take time before they can use this speech ability to go to different places.
Without reiterating the discussion on whether GPT-like programs actually speak or if they imitate speech (cf. 30 December 2022), I will only note my disagreement with the classical objections against computer intelligence. Philosophy and linguistics teachers said and are saying that computers cannot think like humans. I want to address two objections, old and new: John Searle and Noam Chomsky.
-+-+-+-+
Chinese Room (John Searle)
'Imagine me in a closed room,' said Stanford Professor Searle forty years ago:
They told you that there is a Chinese student inside who does not speak English. You scribble a question in Chinese and pass the paper under the door. Even though I don't understand the shape you drew, I identify it using the books inside, copy onto the paper the answer shown in the book and hand it back. If the books are enough, I will make you believe that I know Chinese very well.

“The computer can respond to you like a human,” Searle continues. ‘But it does not know the meaning of its answers any more than I know Chinese. Don't fool yourself.'
I do not think this metaphor is valid any more (if it ever was). Back then, communication with computers was just like Searle's Chinese Room. For example, while I was doing my Master's, I was communicating with the computer by feeding it the cards I punched in the machine. If my program was flawed, the computer answer would be nonsensical. I tried to understand that nonsense and the next day punched new cards and fed it a different program. I learned to write better programs, but the computer did not learn anything because it continued to implement to the letter the programs I wrote.
Not so now. GPT and similar software are not passive agents. They monitor the results of the transaction and improve themselves, and they become more accurate next time. Thanks to a feedback loop that is not in the Chinese Room metaphor, the program constantly rearranges its internal settings. By repeating this cycle automatically millions of times, the computer learns to speak like a human.
-+-+-+-+
Noam Chomsky's objection
Chomsky thinks statistical inventions such as ChatGPT are actually obstacles on the way to true artificial intelligence (Noam Chomsky: The False Promise of ChatGPT, New York Times, 8 Mart 2023).
The human mind is not, like ChatGPT and its ilk, a lumbering statistical engine for pattern matching, gorging on hundreds of terabytes of data and extrapolating the most likely conversational response or most probable answer to a scientific question. On the contrary, the human mind is a surprisingly efficient and even elegant system that operates with small amounts of information; it seeks not to infer brute correlations among data points but to create explanations. (Noam Chomsky: The False Promise of ChatGPT, New York Times, 8 Mart 2023).
Chomsky's article is not a scientific article, but a polemic, moreover, it is a polemic that escapes into occasional hyperbole. So maybe it wasn't worth mentioning, but I know there's legacy respect for Chomsky. I wanted to register my own opinion against those who might only read the newspaper headlines and believe AI efforts to be fraudulent solely because Chomsky says so.

It is absurd discussing whether the computer thinks like a human. Because we do not know how the brain works, most of the discussion would have to remain at the level of "computer is not made of meat, then it cannot think like a human". I think the important thing is whether the computer can do the job like a human. So a functional description of artificial intelligence is enough for me. This is actually a return to Turing test.
GPT and its equivalents have started to produce 'work like a human' in some areas. These are not yet things that will make big changes beyond some conveniences. But I think that they will reach the level where they can do very complex jobs in different fields in a short time. To explain why I think this way, I must start over from the beginning.
-+-+-+-+
Transformer technology
The acronym GPT stands for Generative Pretrained Transformer. It is a term created by OpenAI. Initial GPT (Radford, 2018) code was not shared; The next two GPTs were announced along with their code copied to Github.
OpenAI stopped sharing software once the tech's prowess was proven and competitive concerns prevailed. The code for GPT-3.5/ChatGPT released last December and GPT-4 this month are not shared.
GPT is the OpenAI implementation of the 'Transformer' technology, which we first met in 2017 thanks to an article published by Google employee Vaswani et al. (2017). This technology, which indexes the entire vocabulary of a language and reads millions of publications written using these words, reducing the connections between words to probability relations defined by billions of parameters, is called Large Language Models (LLM) in the scientific literature.
LLM technology starts with Vaswani (2017), but I think Radford (2018) GPT-1 article, which describes the first application, is an easier starting point for newbies.
The underlying technology is the ability to read the beginning of a paragraph and guess what the most likely continuation will be. Radford (2018) mathematically expresses this skill as the maximization of the following probability function:
To explain the practical application of this equation, I asked ChatGPT:
The underlying technology of GPT models is to read the beginning of a paragraph and guess what the most likely continuation would be. Radford (2018) put this mathematically as...
This is its answer:
It is not accurate to say that the underlying technology of GPT models is solely to read the beginning of a paragraph and guess the most likely continuation. While GPT models do use probabilistic language modeling to generate text, they are much more complex than SIMPLY guessing the most likely next word or phrase.
That being said, the statement you have provided does have some basis in Radford et al.'s (2018) paper, "Improving Language Understanding by Generative Pre-Training". In that paper, the authors describe the use of a self-supervised learning technique called masked language modeling, in which a certain percentage of words in a text are randomly masked, and the model is trained to predict the masked words based on the surrounding context.
So, while Radford et al. do describe a mathematical formulation of the masked language modeling process, it is important to note that this is just one aspect of the GPT model, and the model's overall ability to generate coherent and fluent text goes beyond simply predicting the most likely next word based on the beginning of a paragraph.
Although ChatGPT grumbles, I will insist on my interpretation of the Radford(2018) paper. For example, the 46th word of the text above is 'SIMPLY' (I used capital letters for easy recognition). As ChatGPT figures out this text, it examines the previous 'k' words to determine the next most likely word. Its decisions are directed by the outcome of a pre-trained parameterized artificial neural network of N parameters. N is a measure of model size. I have listed a few in the table below::
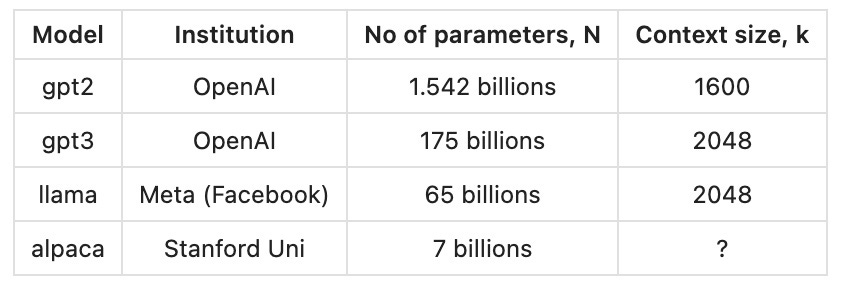
The values of these billions of parameters are set in pretraining done by supercomputers and such pretraining takes weeks. After the parameter values are fixed, it is very fast for the model to perform the given tasks. That's why ChatGPT can instantly answer your questions over the internet.
Machine intelligence may be a complex and wasteful system at first because it is at the beginning of its evolution. Compared against the highly evolved operating system of the human brain with its 86 billion neurons , machines will need maybe 86 trillion parameters to achieve the same performance. We are now short by a factor of 500 (ChatGPT parameters = 176 billion). However, we are already seeing that machine intelligence can do some things as well as humans.
-+-+-+-+
What tasks suit LLMs better?
A 400-author article (Srivastava…, 2022), published nine months ago, tried 204 different tasks and examined which tasks BDMs did well and which ones they failed, and how performance changed with model size. Here is the summary in a single graphic:
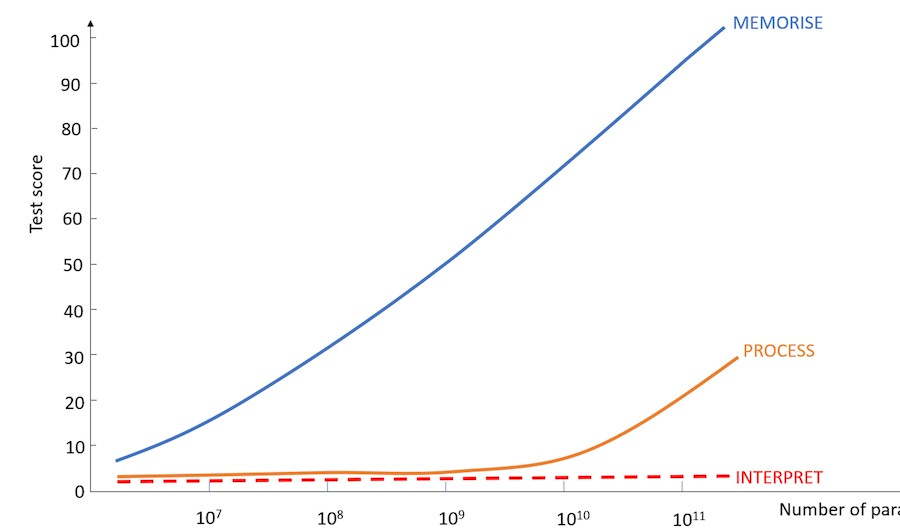
Memorise
The larger the model, the better the tasks that rely on rote knowledge. For example, the qa_wikidata test has fill-in-the-blank questions:
Question : ‘2000 Summer Olympics were held in ....’
Correct Answer : Australia The new model parameter numbers (150 - 200 billion) were sufficient to give correct answers to almost all such questions.
Process
In operations that require several steps, performance is poor. The largest models have yet to pass 30% accuracy. Let's take an example (modified_arithmetic texts):
Question : In the following series, what should be the entry for the last line?
100 + 200 -> 301
838 + 520 -> 1359
343 + 128 -> 472
647 + 471 -> 1119
64 + 138 -> 203
498 + 592 -> ____
Correct Answer: 1091The GPT-3 scored 20 out of a hundred in this test. I think the level of success will increase in future larger models.
Interpret/Commentary
The final group tests consist of questions that require interpretation. They are based on human judgment and cannot be solved with memorized knowledge. Let's take an example (movie_dialog_same_or_different):
Text: 'You're asking me out. That's so cute. What's your name again? Forget it.'
Question: In the above movie dialogue, "That's so cute" and "What's your name again?" are told by the same person or different people?
Answer: The same.It is not that difficult for a person to answer such questions, but BDMs have completely failed.
If the number of model parameters reaches trillions in the future, will performance improve? It is difficult to say, but as the number of parameters increases, more success in this task group will not surprise me.
-+-+-+-+
LLM Engineers?
GPT-4 reportedly knows enough law to pass US bar exams. Engineering knowledge is a little more difficult. Computer programs can learn law by reading legal papers, but they cannot learn engineering by reading engineering books and reports. They may learn how to speak and write like engineers, but not how to calculate. There are various reasons and I think the most important ones are:
Mathematical equations cannot be learned with the Transformer method because different sources use different symbols and different formats.
Even though the same symbols had been used, since the mathematical symbols domain is not continuous like the domain of words, it is not possible to use gradient descent and similar optimization techniques.
Finally, engineered products have to be reliable, with reliability above 99.99% for most products. The only way to ensure this reliability in calculations is to solve the equations with high mathematical precision, not by estimating the most probable result using statistical methods.
LLMs cannot be engineers using only the transformer technique but they can learn to run the necessary programs for an engineering task. In this case, the customer talks to the LLM as the main contractor and LLM contacts additional special engineering modules to finish the job.
For example, let's say you need a bridge design. Engineer LLM can:
first by talking/writing with the customer, understands exactly what the customer wants;
lists the functional specifications of this bridge together with the customer;
sends this list to a different specially trained computer program and receives the list of tasks necessary for the preparation of specifications, eg traffic detection, ground surveys, town planning and scanning of municipal legislation, etc.
Necessary studies and scans are made;
The results of the study, the list of all learned and functional requirements are sent to another subcontractor program and the specification is prepared automatically;
When the draft specification comes from the subcontractor program, LLM and the customer together revise and finalize the specification;
The specification is sent to the design program, this program can activate different calculation modules;
The report from the design is presented to the customer; the client has the result checked by another independent program;
According to the report from the inspector, the design can be revised again;
and so on, and so on.
I have given an example of civil engineering so that non-engineer readers will understand it more easily. Process stages are guesswork, not information, but it is enough to explain what I mean.

In addition to the main LLM, which maintains the main contact with the customer and regulates the information exchange and division of labor, there are additional programs in this scheme. I call them subcontractors because these programs communicate with the main LLM, not the client. It will be desirable to have communication between the main LLM and its subcontractors using natural language (English, Turkish, Chinese, etc., depending on country) in order to facilitate human supervision at all levels of the project plan. Therefore, I think that the user interfaces of all the programs included in the project will be based on LLM. This requires some plugins in LLM software but I hope these plugins will be available soon.
-+-+-+-+
Engineering Faculty
We will see LLM program packages providing engineering services in the next ten years. I think universities and especially engineering faculties should start asking the following questions while watching this issue very closely:
How do we train new engineers to work in a business world where there are computer programs that start from the functional specification list and take the job with the customer all the way to final design and project planning?
If computer programs can provide qualified and detailed assistance, are separate engineering disciplines still needed?
Finally, how can engineering faculties contribute to the writing of these new programs we are talking about?
We are entering an interesting period as engineers..
References
Anderson, P. W. (1974). More is different: broken symmetry and the nature of the hierarchical structure of science. Science, 177(4047), 393-396.
Engels, F. (1883) Dialectics of Nature, Marxist Internet Archive.
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8), 9.
Srivastava, A., Rastogi, A., Rao, A., Shoeb, A. A. M., Abid, A., Fisch, A., ... & Kim, H. (2022). Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.